How much latency can we tolerate? The answer shapes everything that follows: what can be built, how complex the system will become, and whether users will feel like they are having a conversation or waiting in a queue.
In a previous post, I argued that voice isn't text with audio bolted on. This post is about what comes next: once you accept that voice is a different paradigm, how do you actually architect for it?
By the end, you'll have a practical framework for choosing the right pipeline tier for your use case, and an upgrade path as your product's conversational demands increase.
There are four distinct pipeline architectures for voice AI, each with different latency profiles, complexity costs, and use-case fits. Through my prototypes I've made mistakes on both ends (jumping to the most complex option when something simpler would have worked, and shipping something too simple that felt broken in practice); some of the lessons here go back to my 2025 builds. The right architecture depends on what your users need to feel during the conversation, and that's a more nuanced question than it sounds.
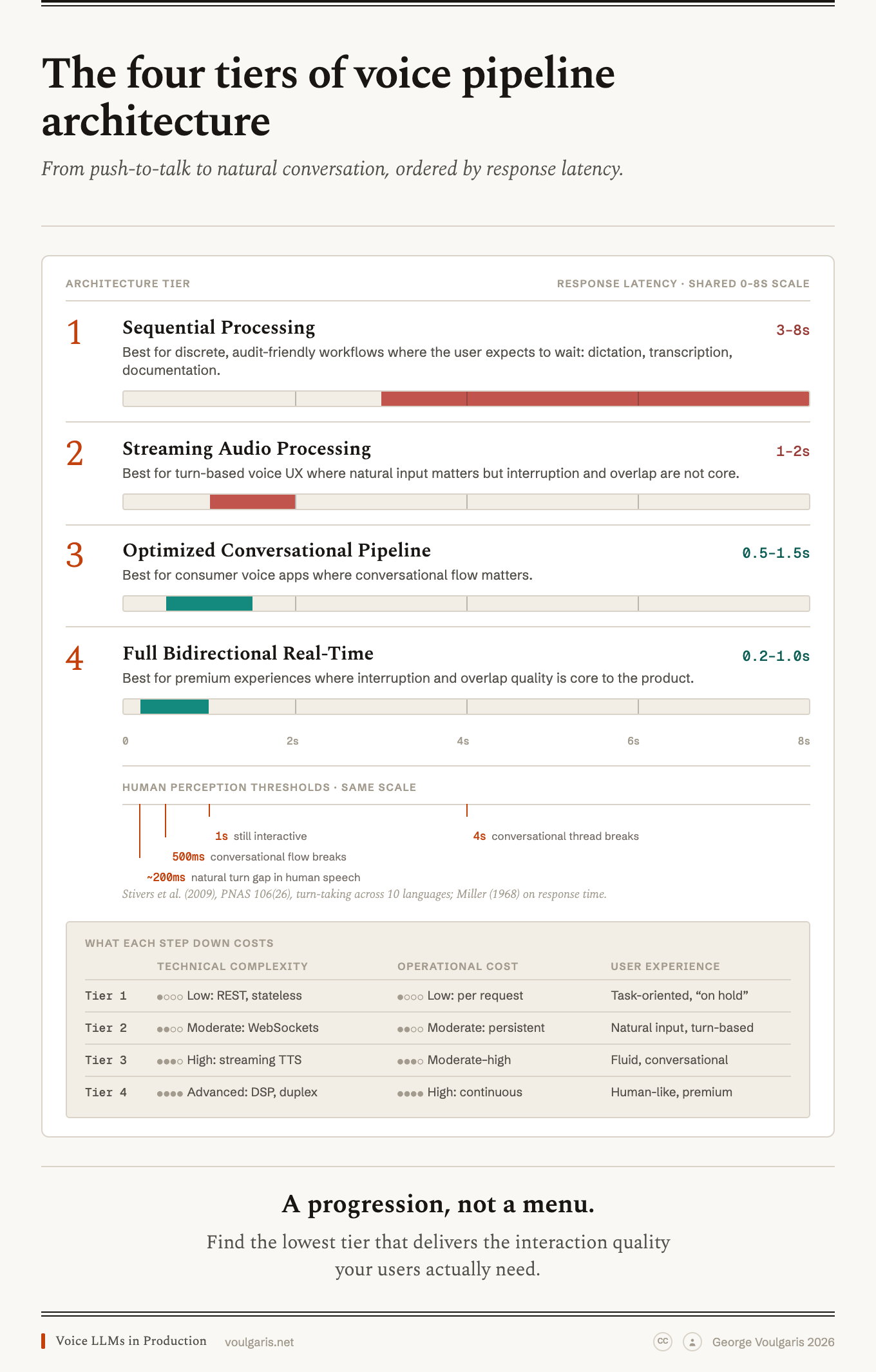
Fig. 1: The four tiers of voice pipeline architecture on a shared 0–8s latency scale, with human turn-taking perception thresholds and what each step down costs in complexity, operating cost, and user experience. Image by author.
The Four Tiers
Think of voice pipeline architectures as a progression, not a menu. Each tier builds on the concepts of the previous one, trading simplicity for responsiveness. The boundaries between tiers aren't hard lines; the latency ranges overlap in practice, and hybrid approaches are common. But the architectural patterns are distinct enough to reason about separately.
A note on axes before diving in: most current write-ups classify voice systems by what is inside the box, a chained STT→LLM→TTS stack versus a native speech-to-speech model. The four tiers classify the interaction contract instead: how fast the system responds, and whether it can listen while speaking. A chained stack and a native model can both land at Tier 3 or Tier 4.
Tier 1: Sequential Processing (3–8 seconds latency)

Fig. 2: Tier 1, Sequential Processing: three discrete, stateless stages. Buffering, synthesis, and network hops push end-to-end latency past 3 seconds. Image by author.
This is the architecture that feels intuitive because it maps onto how we think about conversation: hear the words, understand the meaning, generate a response, speak it back. Speech-to-text, language model, text-to-speech: three discrete services with clear interfaces between them.
The appeal is that failure modes are predictable. You can swap providers independently, debug each stage in isolation, and most importantly, reuse your existing text-based LLM infrastructure as-is. Standard REST APIs, stateless request-response patterns, the infrastructure you know and trust.
For certain use cases, it genuinely is the right choice. The determining factor isn't the domain; it's the interaction pattern. A doctor dictating notes after a patient visit has no need for sub-second responses; accuracy and structured output matter far more. Same for legal transcription, compliance documentation, or any workflow where the user initiates a discrete task and waits for a result. Sequential processing lets you optimize each component independently and maintain clear observability throughout.
The problem is latency. Each handoff between services adds time. Speech-to-text needs audio buffering (100–200ms before you can even start inference). Text-to-speech adds another 100–200ms after the LLM finishes. Network round-trips to cloud services add more. The cumulative effect routinely pushes response times past 3 seconds. As I covered in the earlier post, pauses longer than 500ms break conversational flow. Three seconds doesn't feel like a conversation; it feels like being put on hold.
Best for: discrete, audit-friendly workflows where the user expects to wait (dictation, transcription, documentation).
Tier 2: Streaming Audio Processing (1–2 seconds latency)

Fig. 3: Tier 2, Streaming Audio Processing: a persistent WebSocket feeds overlapping audio chunks to continuous STT, which emits progressively revised partial transcripts; VAD decides when the turn is over. Image by author.
Streaming introduces continuous listening, the system processes audio in overlapping chunks rather than waiting for the user to finish speaking. This enables natural voice activation without requiring a button press, and handles longer utterances more gracefully.
The architectural shift is moving from stateless HTTP requests to persistent connections (typically WebSockets), and the system must handle partial transcripts that get revised as more audio arrives. Your business logic now receives a stream of increasingly confident interpretations rather than a single final transcript. This changes how you write downstream code: you need to handle provisional results and know when to act versus when to wait for refinement.
The key engineering challenge is voice activity detection (VAD). The system must decide in real-time: is this a pause for thought, or has the user finished their utterance? Get it wrong and you either interrupt them mid-thought or leave dead air while they wait. Tuning VAD thresholds consumed more of my time than I expected. The right sensitivity varies by use case, and what works in a quiet test environment falls apart with background noise and was accentuated by “echo”, which means VAD being triggered by the system’s own response through speakers.
This works well for voice assistants, dictation systems, and customer service interfaces. Any application where users expect natural speech input but the interaction is still fundamentally turn-based: user speaks, system responds.
Best for: turn-based voice UX where natural input matters, but interruptions/overlap aren’t core to the product.
Tier 3: Optimized Conversational Pipeline (0.5–1.5 seconds latency)

Fig. 4: Tier 3, Optimized Conversational Pipeline: synthesis begins on the LLM's first tokens; a user barge-in truncates the response and the unspoken tail is discarded. Image by author.
This is where the architecture stops feeling like a walkie-talkie and starts feeling like a conversation. The critical optimization: text-to-speech begins generating audio the moment the first tokens come back from the language model, rather than waiting for the complete response. The system starts speaking before it's done thinking.
This requires two things your Tier 2 system probably didn't need: a language model that supports token-level streaming (many do now, but your integration needs to handle it), and a TTS engine with a streaming input API that can begin synthesis from a partial sentence. Not all TTS providers support this. If yours requires a complete text input, you'll either need to switch providers or implement a buffering strategy that accumulates enough tokens to form a natural-sounding phrase before sending each chunk.
Other optimizations at this tier include using smaller, fine-tuned models that sacrifice some general capability for dramatically faster response times, and adding voice interruption handling so users can interject naturally. The system must now manage partially-generated responses that might get cut short mid-sentence, which introduces state management complexity that lower tiers don't face. When a user interrupts, do you discard the unspoken portion or incorporate the interruption into context? These are design decisions with no universally right answer.
("Barge-in" is the industry term for a user interrupting the system mid-response, and having the system detect and adapt in real time.)
For the user, the experience difference from Tier 2 is noticeable. Responses begin arriving fast enough that the interaction starts to feel like a dialogue rather than a series of exchanges. It's not instant; you can still perceive a beat before the system responds, but it's in the range where most people stop consciously noticing the delay.
Any interaction where the user expects conversational flow can potentially be implemented with a streaming architecture: consumer voice apps, mobile assistants, smart home devices, interactive content, voice-driven workflows. The sweet spot for most consumer-facing applications.
Best for: consumer-facing voice apps where conversational flow matters, but full-duplex interruption handling is not a requirement.
Tier 4: Full Bidirectional Real-Time (0.2–1.0 seconds latency)

Fig. 5: Tier 4, Full Bidirectional Real-Time: both audio streams stay open; echo cancellation subtracts the system's own voice, and the duplex controller keeps talking through backchannels or cuts TTS on barge-in. Image by author.
This is the frontier: true duplex communication where the system can speak and listen simultaneously, handle natural interruptions, overlap speech, and manage seamless turn-taking. Both directions of audio are being processed continuously.
The architectural change from Tier 3 is significant. In the optimized pipeline, speaking and listening are still technically alternating: the system pauses input processing while speaking, or uses simple heuristics to detect barge-in. In full bidirectional, both streams run simultaneously. This means echo cancellation becomes critical (the system must subtract its own voice from the incoming audio to hear the user), and context management gets substantially harder (the system must integrate what it's hearing with what it's currently saying). Some implementations at this tier use native speech-to-speech models that process audio end-to-end without an intermediate text representation, while others run the traditional STT→LLM→TTS stack but with both input and output streams active simultaneously. The system genuinely listens while it speaks, rather than alternating turns with some overlap at the edges (which is what Tier 3 does).
The experience delta is real. The system doesn't just respond faster; it responds differently. It can overlap speech naturally, produce backchannel signals like ("mm-hmm") while the user is still mid-sentence, which is how they work in human conversation. (Backchannel signals are possible at Tier 3 too; ElevenLabs and others produce them without full duplex, but only during the system's own turn, not overlapping with the user's speech.) Tier 4 also handles interruptions without the jarring stop-and-restart of lower tiers. Whether this matters depends entirely on your use case. For a voice agent handling insurance claims, Tier 3's response speed is typically sufficient. For high-touch experiences like coaching, language tutoring, or premium concierge, conversational naturalness is the product. In those cases, Tier 4 can be the difference between something users tolerate and something they seek out.
But implementation requires deeper audio engineering knowledge, and the operational costs are meaningfully higher. Persistent duplex connections cost more per minute, consume more compute, and scale on concurrent connection capacity rather than request throughput.
This pipeline shines where users will notice and judge the quality of the interaction itself: worth the investment when conversational naturalness directly drives your business metrics.
Best for: premium experiences where interruption and overlap quality is a core part of the product.
How to Choose
The decision isn't really about latency alone; it's about the interaction pattern your users expect, constrained by what your team can build and operate.
-
What interaction are you building? A discrete task the user initiates and waits for (Tier 1)? A natural turn-based exchange (Tier 2)? A flowing conversation (Tier 3)? An experience indistinguishable from talking to a person (Tier 4)? This is the primary filter, and it eliminates most options quickly.
-
What can your team build? Sequential processing uses patterns every backend engineer knows. Streaming requires comfort with WebSockets and handling provisional data. Optimized pipelines need someone who understands streaming TTS integration and interruption state machines. Bidirectional demands real-time API expertise: echo cancellation, acoustic feedback, real-time signal processing.
-
What can you afford to operate? The tiers differ in operational cost in ways that compound at scale. Stateless request-response is cheap. Persistent WebSocket connections are more. Continuous bidirectional audio streaming with echo cancellation: meaningfully more still. The tier you choose affects your unit economics per conversation-minute.
These three questions are entangled, not sequential. Complexity and capacity might rule out tiers before you evaluate interaction patterns, and your cost structure might eliminate options before you consider user experience. The goal is to find the lowest tier that delivers the interaction quality your users actually need.
The Mistakes I Made (So You Don't Have To)
Jumping straight to full duplex. My first instinct with one prototype was to go full Tier 4: real-time, full-duplex, the works. It made for an impressive demo. It also meant I spent most of my time fighting echo cancellation edge cases and race conditions instead of refining the actual conversation experience. The use case would have been perfectly served by Tier 2.
Underestimating how bad 4 seconds feels. On another project, I started with a clean sequential pipeline because it was the fastest to stand up. Technically it worked. But the first time I tried having an actual back-and-forth with it, the pauses were deadening. I ended up rebuilding the pipeline under time pressure, which is never fun.
Not planning the upgrade path. Moving from Tier 1 to Tier 2 is straightforward: you're primarily adding VAD, switching to a persistent connection, and handling partial transcripts. The business logic and LLM integration stay largely intact. Tier 2 to Tier 3 is a moderate refactor; you need to restructure how TTS consumes LLM output (streaming integration rather than waiting for complete text) and add interruption handling. Tier 3 to Tier 4 is close to a full re-architecture. The simultaneous bidirectional audio processing, echo cancellation, and parallel stream coordination are fundamentally different from a sequential-with-optimizations approach. I didn't think about this until I was mid-refactor, and some of my early design choices made the jump harder than it needed to be.
Ignoring operational cost. Persistent bidirectional connections cost meaningfully more per conversation-minute than stateless request-response patterns. I didn't fully internalize this until I ran the numbers on what scaling would actually look like.
There's also a hard constraint most providers impose: session duration limits. This introduces a number of new issues for systems that depend entirely on voice control: detecting the wake up phrase, and managing context across “stitched” sessions. The OpenAI Realtime API, LiveKit sessions, WebRTC connections: none of them give you an infinite call. You need to design for graceful session handoffs or reconnections, which adds another layer of complexity. The tier you choose doesn't just affect development complexity; it affects your unit economics and your session architecture.
Designing for Evolution
The architecture you choose doesn't have to be permanent, and you don't have to build everything from scratch. By mid-2026, the platform ecosystem has absorbed much of the pipeline complexity. OpenAI's Realtime API and Google's Gemini Live API are both generally available with native speech-to-speech models at Tier 4, and Amazon's Nova 2 Sonic unifies speech understanding and generation in a single model. LiveKit and Pipecat provide open-source real-time infrastructure you can self-host. Vapi, Retell AI, and ElevenLabs Agents give you managed Tier 3/4 pipelines with API-level simplicity. Deepgram and AssemblyAI handle the STT layer with streaming and domain-tuned models. These tools don't eliminate architectural decisions (you still need to choose the right tier and design your conversation logic), but they dramatically reduce the audio-engineering surface area you have to own.
A few things I wish I'd done from the start, regardless of which platform I used:
Keep your business logic decoupled from audio handling. The conversation logic (what your system says, when it calls tools, how it manages context) should be independent of how audio gets in and out. If your intent parsing is tangled with your WebSocket management, every tier change requires rewriting both.
Abstract the transport layer early. Whether audio arrives via REST, WebSocket, or a real-time streaming SDK, the interface your application code sees should be the same: a stream of transcribed utterances and a way to send responses. This abstraction costs almost nothing at Tier 1 and saves significant time at every subsequent upgrade.
Instrument from day one. Measure end-to-end latency per turn, broken down by component (STT time, LLM time, TTS time, transport overhead). This data tells you exactly which tier transition will help, and whether your bottleneck is even in the pipeline architecture or somewhere else entirely.
The choice between voice pipeline architectures should be driven by the interaction your users expect, not by technological novelty. Start with the simplest architecture that delivers the right experience, and make the next upgrade easy.
— George · voulgaris.net